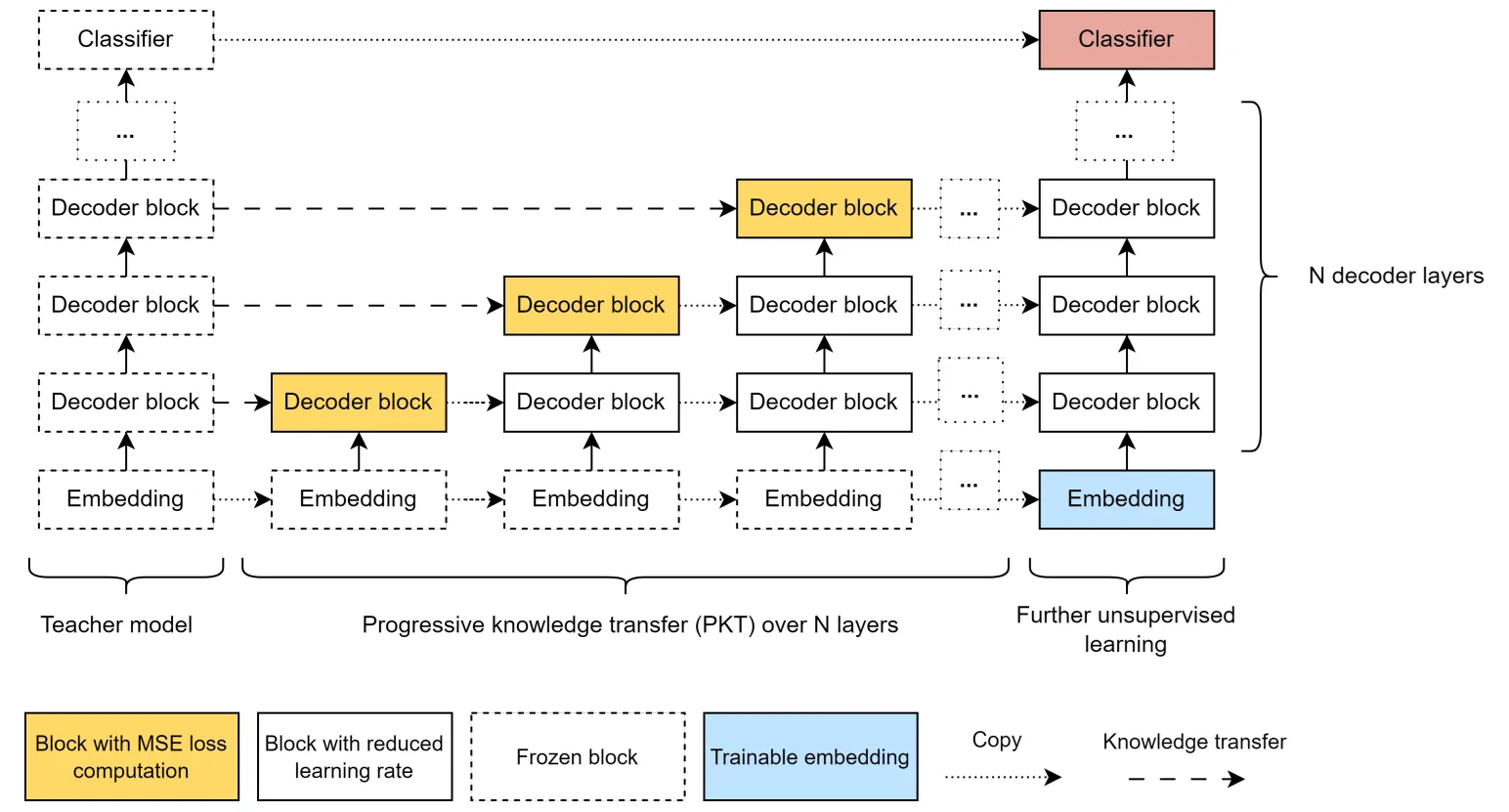
We evaluated the effectiveness of distillation to transfer knowledge from an attention-based transformer to a Hyena-based transformer, a state-space language model. Our paper was accepted as an ICML 2024 workshop paper at ES-FoMo-II, and is accessible at arxiv.org/abs/2401.17574.
Our Paper’s Contributions
- Given that state-space models (such as Hyena) have lower computational complexity, we evaluate whether distilling the “knowledge” from an attention transformer to a Hyena model of the same size (70M) can preserve the attention transformer’s natural language understanding capabilities
- Using lm-eval, we notice that many tasks experience a slight-to-considerable drop in accuracy on benchmarked tasks, though WSC experiences a noticeable increase from 0.37 to 0.59.
Limitations
- Due to limited compute at the time, we evaluated all our work on a 70M Pythia model. While our results are encouraging, we would need to scale up (at least to a 1B model) to obtain practical results.